
Nick Brown pointed me to a new paper, “The Affect of Incidental Environmental Elements on Vote Alternative: Wind Velocity is Associated to Extra Prevention-Targeted Voting,” to which his response was, “It makes himmicanes look believable.” Certainly, one of many authors of this text had come up earlier on this weblog as a coauthor of paper with fatally-flawed statistical analysis. So, between the overall theme of this new article (“How would possibly irrelevant occasions infiltrate voting selections?”), the precise declare that wind velocity has massive results, and the monitor report of one of many authors, I got here into this in a skeptical way of thinking.
That’s high quality. Scientific papers are for everybody, not simply the true believers. Skeptics are a part of the viewers too.
Anyway, I took a take a look at the article and replied to Nick:
The paper is an effective “train for the reader” form of factor to search out how they managed to get all these pleasantly low p-values. It’s not as blatantly apparent as, say, the work of Daryl Bem. The humorous factor is, again in 2011, plenty of individuals thought Bem’s statistical evaluation was state-of-the-art. It’s only in retrospect that his p-hacking seems about as crude because the faux images that fooled Arthur Conan Doyle. Determine 2 of this new paper seems so spectacular! I don’t actually really feel like placing within the effort to determining precisely how the trick was executed on this case . . . Do you might have any concepts?
Nick responded:
There are some hilarious errors within the paper. For instance:
– On p. 7 of the PDF, they declare that “For Brexit, the “No” choice superior by the Stronger In marketing campaign was seen as clearly prevention-oriented (Imply (M) = 4.5, Customary Error (SE) = 0.17, t(101) = 6.05, p
Nick then got here again with extra:
I discovered one other drawback, and it’s enormous:
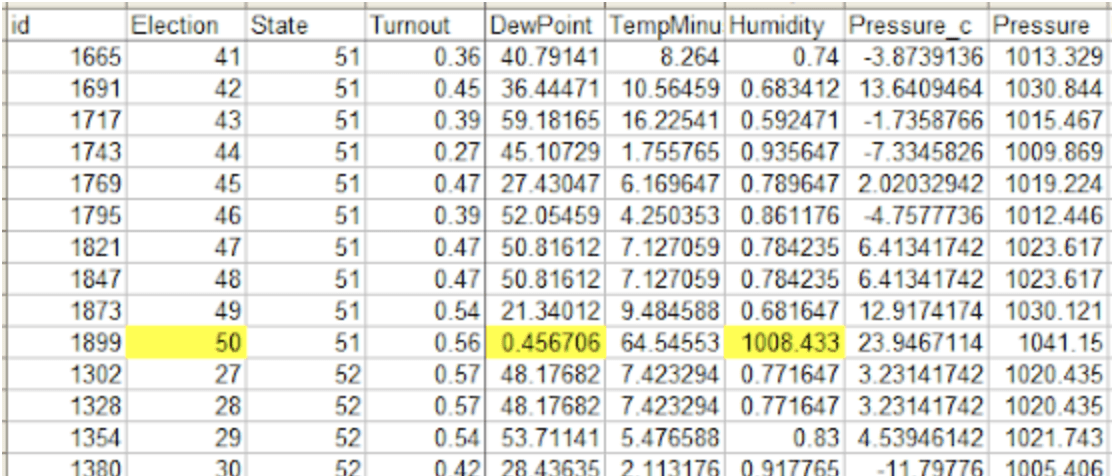
For “Election 50”, the Humidity and Dew Level knowledge are fully borked (“relative humidity” values round 1000 as an alternative of 0.6 and many others; dew level 0.4–0.6 as an alternative of a Fahrenheit temperature barely beneath the measured temperature within the 50–60 vary). After I take away that referendum from the outcomes, I get the hooked up model of Determine 2. I can’t run their Stata fashions, however by my interpretation of the mannequin coefficients from the R mannequin that went into making Determine 2, the worth for the windspeed * situation interplay goes from 0.545 (SE=0.120, p=0.000006) to 0.266 (SE=0.114, p=0.02).
So it appears to me {that a} very huge a part of the impact, for the Swiss outcomes anyway, is being pushed by this knowledge error within the covariates.
After which he posted a blog with further details, together with a hyperlink to some other criticisms from Erik Gahner Larsen.
The massive query
Why do junk science and sloppy knowledge dealing with so usually appear collectively? We’ve seen this rather a lot, for instance the ovulation-and-voting and ovulation-and-clothing papers that used the fallacious dates for peak fertility, the Excel error paper in economics, the gremlins paper in environmental economics, the evaluation of air air pollution in China, the collected work of Brian Wansink, . . . .
What’s happening? My speculation is as follows. There are many useless ends in science, together with some dangerous concepts and a few good concepts that simply don’t work out. What makes one thing junk science is not only that it’s learning an impact that’s too small to be detected with noisy knowledge; it’s that the research seem to succeed. It’s the deceptive obvious success that’s turns a scientific useless finish into junk science.
As we’ve been conscious because the traditional Simmons et al. paper from 2011, researchers can and do use researcher levels of freedom to acquire obvious robust results from knowledge that would properly be pure noise. This effort could be executed on objective (“p-hacking”) or with out the researchers realizing it (“forking paths”), or by way of some combination of the 2.
The purpose is that, on this form of junk science, it’s potential to get very impressive-looking outcomes (similar to Determine 2 within the above-linked article) from nearly any knowledge in any respect! What which means is that knowledge high quality doesn’t actually matter.
In case you’re learning an actual impact, then you definitely need to be actually cautious along with your knowledge: any noise you introduce, whether or not in measurement or by way of coding error, could be anticipated to attenuate your impact, making it more durable to find. While you’re doing actual science you might have a powerful motivation to take correct measurements and hold your knowledge clear. Errors can nonetheless creep in, typically destroying a study, so I’m not saying it could’t occur. I’m simply saying that the motivation is to get your knowledge proper.
In distinction, in case you’re doing junk science, the information aren’t so related. You’ll get robust outcomes a technique or one other. Certainly, there’s a bonus to not trying too carefully at your knowledge at first; that manner in case you don’t discover the consequence you need, you possibly can undergo and clear issues up till you attain success. I’m not saying the authors of the above-linked paper did any of that form of factor on objective; moderately, what I’m saying is that they don’t have any specific incentive to verify their knowledge, so from that standpoint perhaps we shouldn’t be so stunned to see gross errors.
Nick Brown pointed me to a new paper, “The Affect of Incidental Environmental Elements on Vote Alternative: Wind Velocity is Associated to Extra Prevention-Targeted Voting,” to which his response was, “It makes himmicanes look believable.” Certainly, one of many authors of this text had come up earlier on this weblog as a coauthor of paper with fatally-flawed statistical analysis. So, between the overall theme of this new article (“How would possibly irrelevant occasions infiltrate voting selections?”), the precise declare that wind velocity has massive results, and the monitor report of one of many authors, I got here into this in a skeptical way of thinking.
That’s high quality. Scientific papers are for everybody, not simply the true believers. Skeptics are a part of the viewers too.
Anyway, I took a take a look at the article and replied to Nick:
The paper is an effective “train for the reader” form of factor to search out how they managed to get all these pleasantly low p-values. It’s not as blatantly apparent as, say, the work of Daryl Bem. The humorous factor is, again in 2011, plenty of individuals thought Bem’s statistical evaluation was state-of-the-art. It’s only in retrospect that his p-hacking seems about as crude because the faux images that fooled Arthur Conan Doyle. Determine 2 of this new paper seems so spectacular! I don’t actually really feel like placing within the effort to determining precisely how the trick was executed on this case . . . Do you might have any concepts?
Nick responded:
There are some hilarious errors within the paper. For instance:
– On p. 7 of the PDF, they declare that “For Brexit, the “No” choice superior by the Stronger In marketing campaign was seen as clearly prevention-oriented (Imply (M) = 4.5, Customary Error (SE) = 0.17, t(101) = 6.05, p
Nick then got here again with extra:
I discovered one other drawback, and it’s enormous:
For “Election 50”, the Humidity and Dew Level knowledge are fully borked (“relative humidity” values round 1000 as an alternative of 0.6 and many others; dew level 0.4–0.6 as an alternative of a Fahrenheit temperature barely beneath the measured temperature within the 50–60 vary). After I take away that referendum from the outcomes, I get the hooked up model of Determine 2. I can’t run their Stata fashions, however by my interpretation of the mannequin coefficients from the R mannequin that went into making Determine 2, the worth for the windspeed * situation interplay goes from 0.545 (SE=0.120, p=0.000006) to 0.266 (SE=0.114, p=0.02).
So it appears to me {that a} very huge a part of the impact, for the Swiss outcomes anyway, is being pushed by this knowledge error within the covariates.
After which he posted a blog with further details, together with a hyperlink to some other criticisms from Erik Gahner Larsen.
The massive query
Why do junk science and sloppy knowledge dealing with so usually appear collectively? We’ve seen this rather a lot, for instance the ovulation-and-voting and ovulation-and-clothing papers that used the fallacious dates for peak fertility, the Excel error paper in economics, the gremlins paper in environmental economics, the evaluation of air air pollution in China, the collected work of Brian Wansink, . . . .
What’s happening? My speculation is as follows. There are many useless ends in science, together with some dangerous concepts and a few good concepts that simply don’t work out. What makes one thing junk science is not only that it’s learning an impact that’s too small to be detected with noisy knowledge; it’s that the research seem to succeed. It’s the deceptive obvious success that’s turns a scientific useless finish into junk science.
As we’ve been conscious because the traditional Simmons et al. paper from 2011, researchers can and do use researcher levels of freedom to acquire obvious robust results from knowledge that would properly be pure noise. This effort could be executed on objective (“p-hacking”) or with out the researchers realizing it (“forking paths”), or by way of some combination of the 2.
The purpose is that, on this form of junk science, it’s potential to get very impressive-looking outcomes (similar to Determine 2 within the above-linked article) from nearly any knowledge in any respect! What which means is that knowledge high quality doesn’t actually matter.
In case you’re learning an actual impact, then you definitely need to be actually cautious along with your knowledge: any noise you introduce, whether or not in measurement or by way of coding error, could be anticipated to attenuate your impact, making it more durable to find. While you’re doing actual science you might have a powerful motivation to take correct measurements and hold your knowledge clear. Errors can nonetheless creep in, typically destroying a study, so I’m not saying it could’t occur. I’m simply saying that the motivation is to get your knowledge proper.
In distinction, in case you’re doing junk science, the information aren’t so related. You’ll get robust outcomes a technique or one other. Certainly, there’s a bonus to not trying too carefully at your knowledge at first; that manner in case you don’t discover the consequence you need, you possibly can undergo and clear issues up till you attain success. I’m not saying the authors of the above-linked paper did any of that form of factor on objective; moderately, what I’m saying is that they don’t have any specific incentive to verify their knowledge, so from that standpoint perhaps we shouldn’t be so stunned to see gross errors.








{kind=link}