
Again in 2020, main lecturers and researchers on the firm now referred to as Meta put together a large project to check social media and the 2020 US elections — significantly the roles of Instagram and Fb. As Sinan Aral and I had written about what number of paths for understanding results of social media in elections may require new interventions and/or platform cooperation, this appeared like an necessary growth. Initially the concept was for this work to be printed in 2021, however there have been some delays, together with just because among the knowledge assortment was prolonged as what one would possibly name “election-related occasions” continued past November and into 2021. As of 2pm Japanese at the moment, the information embargo for this work has been lifted on the primary group of analysis papers.
I had heard about this challenge again a very long time in the past and, frankly, had largely forgotten about it. However this previous Saturday, I used to be collaborating within the SSRC Workshop on the Economics of Social Media and one session was devoted to results-free displays about this challenge, together with the setup of the establishments concerned and the design of the analysis. The organizers informally polled us with qualitative questions about some of the results. This intrigued me. I had just lately reviewed an unrelated paper that included survey knowledge from consultants and laypeople about their expectations in regards to the results estimated in a discipline experiment, and I assumed this knowledge was useful for contextualizing what “we” realized from that research.
So I assumed it is perhaps helpful, at the very least for myself, to spend a while eliciting my very own expectations in regards to the portions I understood could be reported in these papers. I’ve primarily stored up with the educational and gray literature, I’d beforehand labored within the business, and I’d reviewed a few of this for my Senate testimony back in 2021. Alongside the best way, I attempted to articulate the place my expectations and remaining uncertainty had been coming from. I composed lots of my ideas on my cellphone Monday whereas taking the subway to and from the storage unit I used to be revisiting after which emptying in Brooklyn. I received just a few feedback from Solomon Messing and Tom Cunningham, after which uploaded my notes to OSF and posted a cheeky tweet.
Since then, beginning yesterday, I’ve spoken with journalists and gotten to view the primary textual content of papers for 2 of the randomized interventions for which I made predictions. These evaluated results of (a) switching Facebook and Instagram users to a (reverse) chronological feed, (b) removing “reshares” from Facebook users’ feeds, and (c) downranking content by “like-minded” users, Pages, and Groups.
My important expectations for these three interventions could possibly be summed up as follows. These interventions, particularly chronological rating, would every scale back engagement with Fb or Instagram. This is sensible for those who suppose the established order is somewhat-well optimized for displaying participating and related content material. So among the remainder of the consequences — on, e.g., polarization, information data, and voter turnout — could possibly be partially inferred from that lower in use. This may level to reductions in information data, problem polarization (or coherence/consistency), and small decreases in turnout, particularly for chronological rating. It is because individuals get some arduous information and political commentary they wouldn’t have in any other case from social media. These reduced-engagement-driven results must be weakest for the “comfortable” intervention of downranking some sources, since content material predicted to be significantly related will nonetheless make it into customers’ feeds.
In addition to simply decreasing Fb use (and every thing that goes with that), I additionally anticipated swapping out feed rating for reverse chron would expose customers to extra content material from non-friends by way of, e.g., Teams, together with giant will increase in untrustworthy content material that will usually rank poorly. I anticipated among the similar would occur from eradicating reshares, which I anticipated would make up over 20% of views below the established order, and so could be stuffed in by extra Teams content material. For downranking sources with the identical estimated ideology, I anticipated this would cut back publicity to political content material, as a lot of the non-same-ideology posts will likely be by sources with estimated ideology in the midst of the vary, i.e. [0.4, 0.6], that are much less more likely to be posting politics and arduous information. I’ll additionally word that a lot of my uncertainty about how chronological rating would carry out was as a result of there have been loads of unknown however necessary “particulars” about implementation, comparable to precisely how a lot of the rating system actually will get turned off (e.g., how a lot doubtless spam/rip-off content material nonetheless will get filtered out in an early stage?).
Right here’s a fast abstract of my guesses and the leads to these three papers:
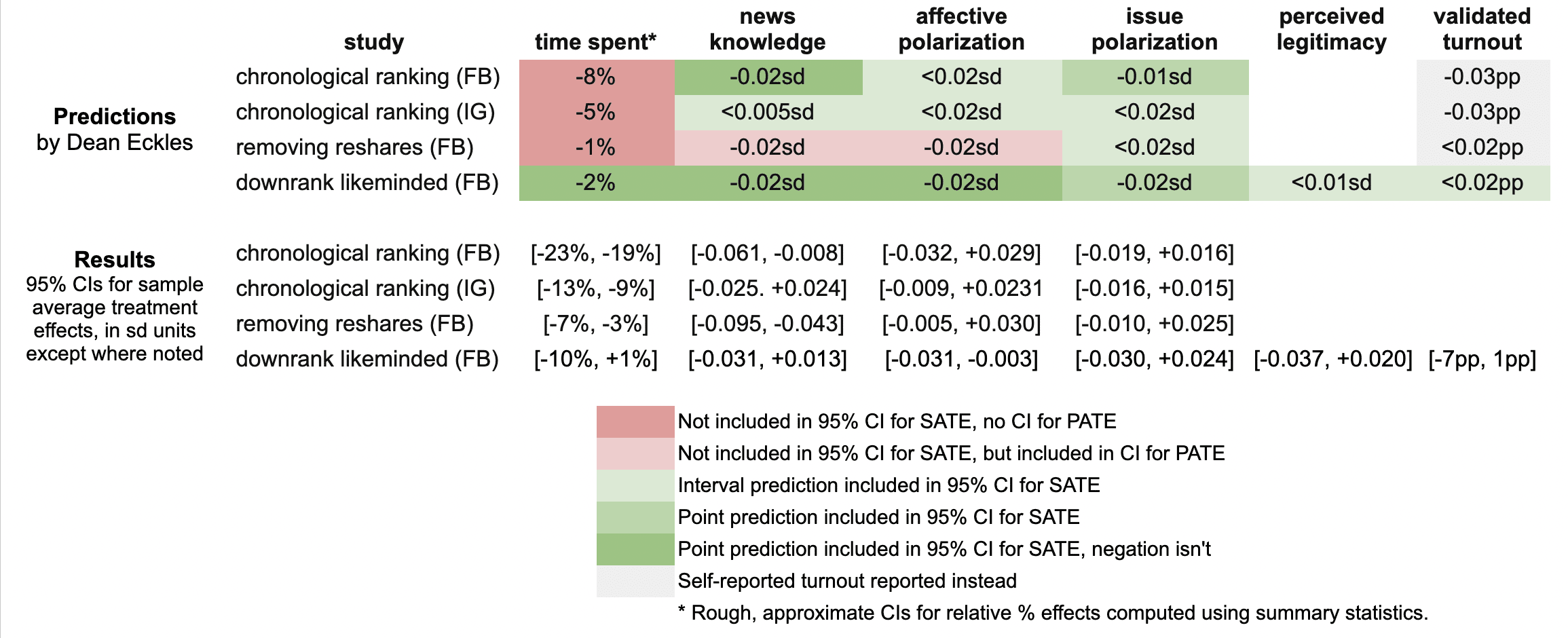
It seems like I used to be unsuitable in that the reductions in engagement had been bigger than I predicted: e.g., chronological rating diminished time spent on Fb by 21%, relatively than the 8% I guessed, which was primarily based on my background data, a leaked report on a Facebook experiment, and this published experiment from Twitter.
Ex put up I hypothesize that that is due to the period of those experiments allowed for continuous declines in use over months, with varied suggestions loops (e.g., customers with chronological feed log in much less, so that they put up much less, so they get fewer likes and comments, so they log in even less and post even less). As I dig into the 100s of pages of supplementary supplies, I’ll be trying to perceive what these declines regarded like at earlier factors within the experiment, comparable to by election day.
My estimates for the survey-based outcomes of major curiosity, comparable to polarization, had been primarily lined by the 95% confidence intervals, aside from two outcomes from the “no reshares” intervention.
One factor is that every one these papers report weighted estimates for a broader inhabitants of US customers (inhabitants common therapy results, PATEs), that are much less exact than the unweighted (pattern common therapy impact, SATE) outcomes. Right here I focus primarily on the unweighted outcomes, as I didn’t know there was going to be any weighting and these are additionally the extra slim, and thus riskier, CIs for me. (There appears to have been some mismatch between the outcomes listed within the speak I noticed and what’s within the papers, so I didn’t make predictions for some reported major outcomes and a few outcomes I made predictions for don’t appear to be reported, or I haven’t discovered them within the dietary supplements but.)
Now is an efficient time to notice that I principally predicted what psychologists armed with Jacob Cohen’s guidelines of thumb would possibly name extrapolate to “minuscule” impact sizes. All my predictions for survey-based outcomes had been 0.02 commonplace deviations or smaller. (Recall Cohen’s guidelines of thumb say 0.1 is small, 0.5 medium, and 0.8 giant.)
Practically all the outcomes for these outcomes in these two papers had been indistinguishable from the null (p > 0.05), with commonplace errors for survey outcomes at 0.01 SDs or extra. That is in step with my ex ante expectations that the experiments would face extreme energy issues, at the very least for the sort of results I’d count on. Maybe by revealed choice, quite a lot of different consultants had totally different priors.
A uncommon p < 0.05 result’s that that chronological rating diminished information data by 0.035 SDs with 95% CI [-0.061, -0.008], which incorporates my guess of -0.02 SDs. Eradicating reshares could have diminished information data much more than chronological rating — and by greater than I guessed.
Even with so many null outcomes I used to be nonetheless sticking my neck out a bit in contrast with simply guessing zero in all places, since in some circumstances if I had put the alternative signal my estimate wouldn’t have been within the 95% CI. For instance, downranking “like-minded” sources produced a CI of [-0.031, 0.013] SDs, which incorporates my guess of -0.02, however not its negation. Alternatively, I received a few of these unsuitable, the place I guessed eradicating reshares would cut back affective polarization, however a 0.02 SD impact is outdoors the ensuing [-0.005, +0.030] interval.
It was truly fairly a bit of labor to match my predictions to the outcomes as a result of I didn’t actually know loads of key particulars about precise analyses and reporting decisions, which strikingly even differ a bit throughout these three papers. So I’d but discover extra locations the place I can, with loads of studying and a little bit of arithmetic, work out the place else I could have been unsuitable. (Be at liberty to level these out.)
I hope that this helps to contextualize the current outcomes with knowledgeable consensus — or at the very least my idiosyncratic expectations. I’ll doubtless write a bit extra about these new papers and additional work launched as a part of this challenge.
It was in all probability an oversight for me to not make any predictions about the observational paper looking at polarization in exposure and consumption of news media. I felt like I had a greater deal with on eager about easy therapy results than these measures, however maybe that was all of the extra purpose to make predictions. Moreover, given the restricted precision of the experiments’ estimates, maybe it might have been extra informative (and riskier) to make level predictions about these exactly estimated observational portions.
[This post is by Dean Eckles. I want to note that I was an employee or contractor of Facebook (now Meta) from 2010 through 2017. I have received funding for other research from Meta, Meta has sponsored a conference I organize, and I have coauthored with Meta employees as recently as earlier this month. I was also recently a consultant to Twitter, ending shortly after the Musk acquisition. You can find all my disclosures here.]








{kind=link}