
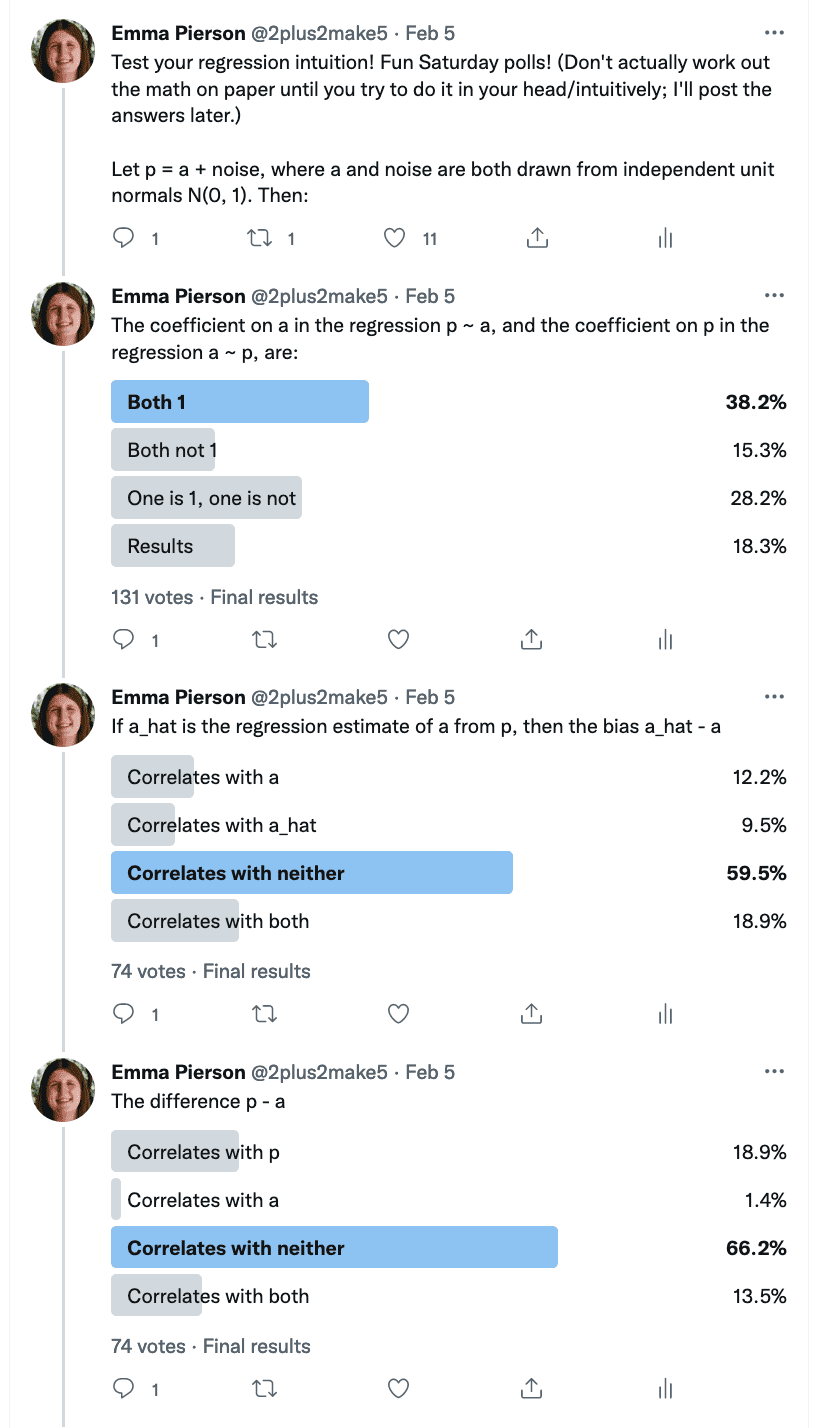
Emma Pierson sends alongside this statistics quiz (screen-shotted beneath—you’ll be able to see the solutions folks gave to every query within the bar graphs):
Pierson writes:
Regardless of the simplicity and ubiquity of the setup, folks have been very dangerous at this quiz—on each query, the bulk reply was incorrect, and on the final two questions, efficiency was worse than random guessing. In fact, Twitter is a bizarre pattern, however I additionally spoke to numerous real specialists—professors of statistics, laptop science, and economics at high universities—who discovered these questions unintuitive as effectively. I believed this is likely to be of curiosity to your weblog since you may be capable of present some helpful instinct or diagnose why folks’s intuitions lead them astray right here.
I responded: I don’t fairly perceive your questions. From query 1, it appear to be “a”, “noise”, and “p” are vectors; I’m picturing size 100 as a result of that’s what I usually do in simulation experiments for sophistication.. However then in query 2, it seems to be like “a” is a scalar, however then the bias can be E(a_hat – a), not a_hat – a. After which the correlation you’re discussing is throughout a number of research. In query 3, it once more looks like “a” and “p” are vectors. I suppose I perceive questions 1 and three however not query 2. I agree that it’s disturbing that so many individuals get this unsuitable. I ponder whether the ambiguous specification is a part of the issue. Or possibly I’m lacking one thing?
Pierson responded:
Right here’s a simulation of the setup I had in thoughts (hopefully an accurate simulation—I don’t actually use R nowadays, however I feel you do):
a = rnorm(500000) noise = rnorm(500000) p = a + noise d = knowledge.body(a, p) # query 1 print(lm(a ~ p, knowledge=d)) print(lm(p ~ a, knowledge=d)) # query 2 a_hat = predict(lm(a ~ p, knowledge=d), d) print(cor(a_hat - a, a)) print(cor(a_hat - a, a_hat)) # query 3 print(cor(p - a, a)) print(cor(p - a, p))At all times laborious to know what folks on Twitter are pondering, however I don’t suppose (primarily based on my conversations with folks) that misunderstandings clarify the unsuitable solutions? Folks appeared to grasp the setup fairly clearly, and I additionally didn’t get any confused questions on it on Twitter.
To which I replied: Oh, you have been defining a_hat as the purpose prediction: I didn’t get that half. I agree that these items confuse folks. It jogs my memory of that different false instinct folks have, that if a is correlated with b, and b is correlated with c, then a have to be correlated with c. Folks additionally appear to have the instinct {that a} might be correlated with b, even whereas b is uncorrelated with a. After which there’s an entire literature in cognitive psychology on super-additive chances (Pr(A) + Pr(not-A) appears to be larger than 1) or sub-additive chances (Pr(A) + Pr(not-A) appears to be lower than 1). Numerous confusion round chance. It’s a jungle on the market.
This is without doubt one of the motivations for the work of Gigerenzer and so on. on reframing issues when it comes to pure frequencies in order to keep away from the confusingness of chance.








{kind=link}