
Shane Frederick, who typically sends me likelihood puzzles, despatched alongside this query:
Amongst married {couples}, what’s your greatest guess about how typically the spouse is taller than the husband?
• 1 in 10
• 1 in 40
• 1 in 300
• 1 in 5000
I didn’t need to cheat so I attempted to consider this one with out doing any calculations or wanting something up. My two sources of knowledge have been my recollection of the distributions of womens’ and mens’ heights (that is in Regression and Other Stories) and no matter I might dredge up from my private experiences with buddies and {couples} I see strolling on the road.
I responded to Shane as follows:
I’m embarrassed to say I don’t know the reply to this query of yours. I’d guess 1 in 10, however I suppose that 1 in 40 just isn’t solely out of the query, on condition that the 2 heights are positively correlated. So possibly I’d guess 1 in 40. However 1 in 10 just isn’t out of the query…
Shane responded:
It’s roughly 1 in 40 if you happen to assumed non assortative mating (simply randomly picked women and men from the respective peak distribution of women and men).
In actuality, it’s nearer to 1 in 300. (Ladies don’t like shorter males; males might not like taller girls, and shorter males don’t marry as typically, partially as a result of they earn much less.)
1 in 300 didn’t sound correct to me. So I did some calculating and a few wanting up.
First the calculating.
compare_heights heights[,2])
cat("Assuming corr is", rho, ": likelihood the spouse is taller is", p_wife_taller, ": 1 in", 1/p_wife_taller, "n")
}
mu
And here is the output:
Assuming corr is 0 : likelihood the spouse is taller is 0.076 : 1 in 13
Assuming corr is 0.3 : likelihood the spouse is taller is 0.044 : 1 in 23
Assuming corr is 0.5 : likelihood the spouse is taller is 0.022 : 1 in 45
Assuming corr is 0.7 : likelihood the spouse is taller is 0.0052 : 1 in 191
Utilizing simulation right here is overkill---given that we're assuming the traditional distribution anyway, it might be simple sufficient to simply compute the likelihood analytically utilizing the distribution of the distinction between husband's and spouse's heights (from the numbers above, the imply is 69.1 - 63.7 and the sd is sqrt(2.4^2 + 2.9^2 - 2*rho*2.4*2.9), so for instance if rho = 0.5 you may simply compute pnorm(0, 69.1 - 63.7, sqrt(2.4^2 + 2.9^2 - 2*0.5*2.4*2.9)), which certainly involves 0.22.)---but brute drive appears safer. Certainly, I initially did the simulation with n=1e4 however then I upped the attracts to 1,000,000 simply to be on the secure aspect, because it runs so quick anyway.
A correlation of about 0.5 sounds proper to me, so the above calculations appears to be in keeping with my authentic instinct that the likelihood could be about 1 in 10 if impartial or 1 in 40 accounting for correlation.
Subsequent, the wanting up. I recalled that sociologist Philip Cohen had posted one thing on the subject, so I did some googling and located this press release:
The common peak distinction between women and men within the U.S is about 6 inches. . . . Cohen additionally analyzed the peak of 4,600 married {couples} from the 2009 Panel Examine of Revenue Dynamics and located that the typical husband's peak was 5'11" whereas the typical spouse was 5'5". Furthermore, he discovered that solely 3.8 % of the {couples} have been made up of a tall spouse and a brief husband . . .
Fiona Macrae and Damien Gayle of the Every day Mail picked up this story and in contrast it to related analysis on {couples} within the U.Ok, the place they discovered that for many {couples} - 92.5 % - the person was taller.
Hmmm . . . 5'5" and 5'11" are taller than the numbers that I might been utilizing . . . maybe the folks within the PSID have been carrying socks?
I additionally discovered this post from Cohen based mostly on information from the 2017 wave of the PSID. He provides these graphs:

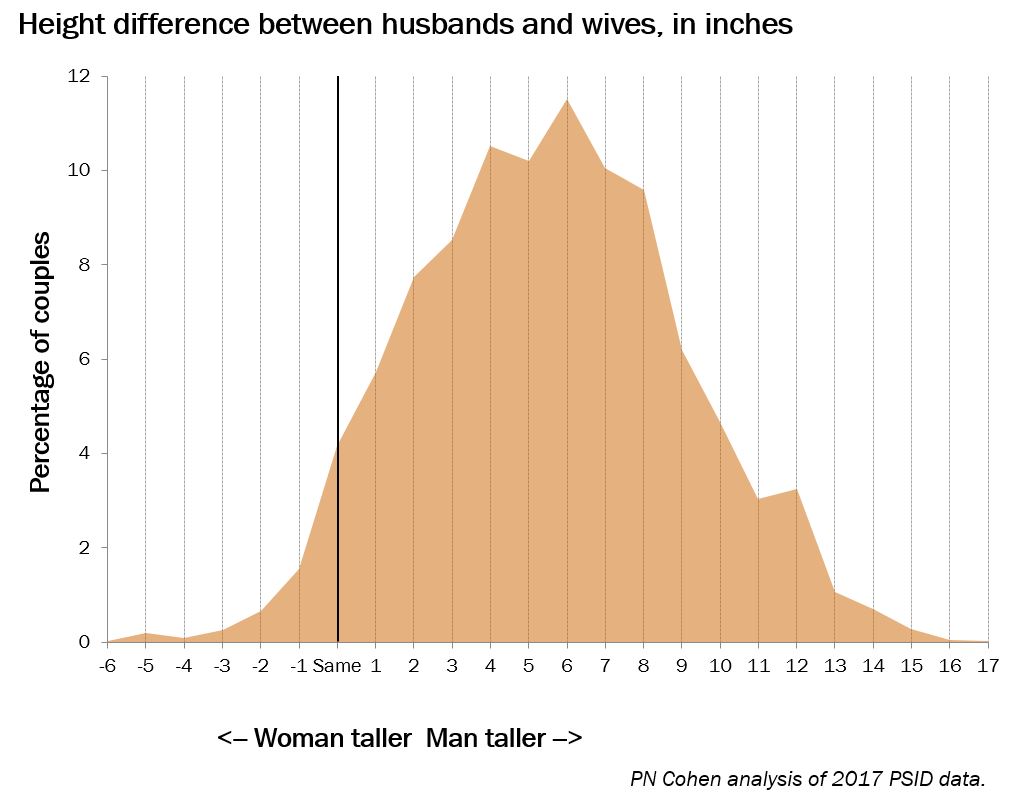
There's one thing bizarre about these graphs---if heights are given to the closest inch, they need to be introduced as histograms, no?---but I believe we are able to learn off the chances.
When you spherical to the closest inch, it seems that there's a 4% likelihood that the 2 members of the couple have the identical peak, a 3% likelihood that the spouse is taller, and a 93% likelihood the husband is taller. So for discrete heights, the likelihood the spouse is taller is roughly 1 in 30. When you enable steady heights and also you allocate a bit lower than half the ties to the "spouse taller than husband" class, then the likelihood turns into one thing like 1 in 25.
Given all this, I questioned how Shane might ever had thought the frequency was 1 in 300. He replied that he acquired his information from this paper, "The male-taller norm in mate choice," printed in Character and Psychology Bulletin in 1980, which stories this:

Simply as an apart, I discover it a bit creepy when researchers use the time period "mate" when referring to married {couples}. Would not "partner" be extra acceptable? "Mate" has this anthropological, scientistic really feel to it.
To return to the substance, there are two mysteries right here. First, how did they calculate that the likelihood of the lady being taller must be solely 2%? Second, how is it that just one of 720 of their {couples} had the spouse taller than the husband?
The reply to the primary query is provided by this desk from the 1980 paper:

Their normal deviations (2.3" inside every intercourse) are too low. That kind of factor can occur once you attempt to estimate a distribution utilizing a small and nonrepresentative pattern. They continued by assuming a correlation of 0.2 between wives' and husbands' heights. I believe 0.2 is just too small a correlation, however once you mix it with the means and normal deviations that they assumed, you find yourself getting one thing cheap.
As to the second query . . . I do not know! This is what they are saying about their information:

My greatest guess is that individuals did some artistic rounding to keep away from the husband's recorded peak being decrease than the spouse's, nevertheless it's laborious to know. I do not fault the authors of that paper from 1980 for utilizing no matter information they might discover; on reflection, although, it appears they have been doing plenty of out-of-control theorizing based mostly on noisy and biased information.
I did some extra googling and located this paper from 2014 with extra from the Panel Examine of Revenue Dynamics. The authors write:
Peak was first measured within the PSID in 1986 after which at each wave beginning in
1999. . . . In 1986, 92.7% of males have been taller than their spouses; in 2009, 92.2% have been taller.
They break the info up into {couples} the place the husbands is shorter than the spouse and {couples} the place they're the identical peak. In 1986, 3.14% of husbands have been shorter and 4.13% have been the identical peak. In 2009, 3.78% have been shorter and 4.00% have been the identical peak. From these information, if you happen to embrace one thing lower than half of the "identical peak" group, you may get an estimate of roughly 5%, or 1 in 20, {couples} the place the spouse is taller than the husband.
So, yeah, between 1 in 10 and 1 in 40. Not 1 in 300.
To be truthful to Shane on this one, this was simply an instance he utilized in considered one of his lessons. It is an fascinating instance the way it's simple to get confused if you happen to simply have a look at one supply, paying homage to some examples we have mentioned earlier on this area:
- What's Russia's GDP per capita?
- The contradictory literature on the consequences on political attitudes of having a son or daughter.
- Numerous claims about the relation between age and happiness.
All these examples function contradictory claims within the literature which might be every made very strongly. The issue just isn't a lot within the disagreement---there is professional uncertainty on these points, together with actual variation---but relatively that the separate claims are introduced as deterministic numbers or as near-certain conclusions. Kinda like this infamous story from Hynes and Vanmarcke (1977) and retold in Active Statistics:

Shane summarizes:
The final message has develop into much more cynical; transmogrifying from “You may’t belief all the things you learn,” to “You may’t belief something you learn.”
I would not fairly put it that strongly; relatively, I might say that it is a good suggestion to search out a number of information sources and a number of analyses, and do not count on that the very first thing you discover will inform the entire story.







{kind=link}